
前言
与传统机器学习不同,深度学习既提供特征提取功能,也可以完成分类的功能。从本章开始我们将学习如何使用深度学习来完成文本表示。
文本型数据的读取与训练与图片等其他格式较为一致的数据不同,文本数据一般不定长,所以如果要进行机器学习的矩阵训练,需要先对文本数据进行归一化处理,把文本转换成可以进行运算的shape相同的向量,然后输入算法进行学习。转换的方法有几种,下面的文本表示方法引用自Datawhale零基础入门NLP赛事 - Task3 基于机器学习的文本分类。
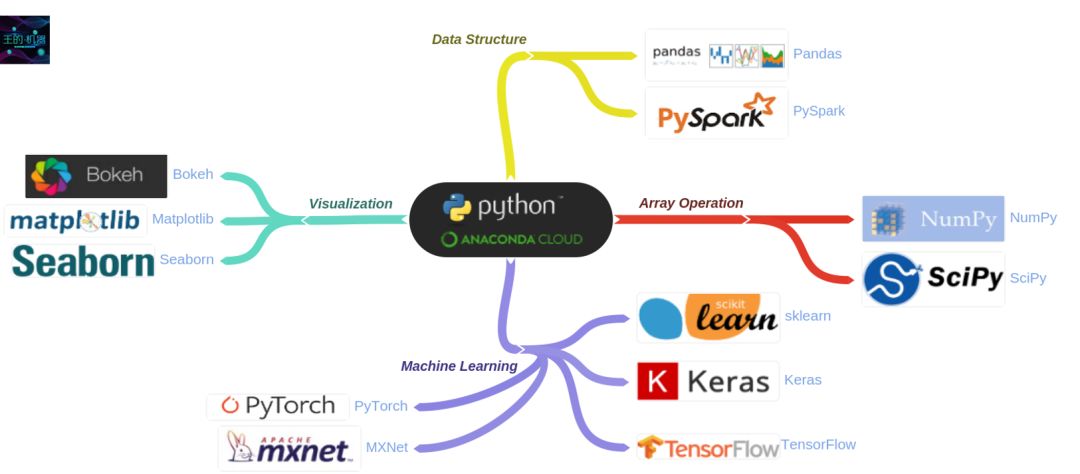
Numpy和pandas是python当中两个非常重要的库,用于配合科学运算和矩阵处理。程序是算法与数据的结合,二者缺一不可,而numpy和pandas就是python中用于处理数据的利器,因此学习这两个package的使用非常重要。在使用matplotlib和seaborn进行数据可视化的时候,就会发现,所有作图的关键在于数据格式的把控,这两个package所提供的API就像是图表的模具,而整理好相应格式的数据就是原料,numpy和pandas就是整理数据的工具。接下来让我们开始学习这两个package吧。在这上一篇博客中我们学习了numpy,这一篇博客中我们来学习pandas。
这是一幅python_package的总览图,由此我们可以大概了解,有哪些很值得我们学习的package。
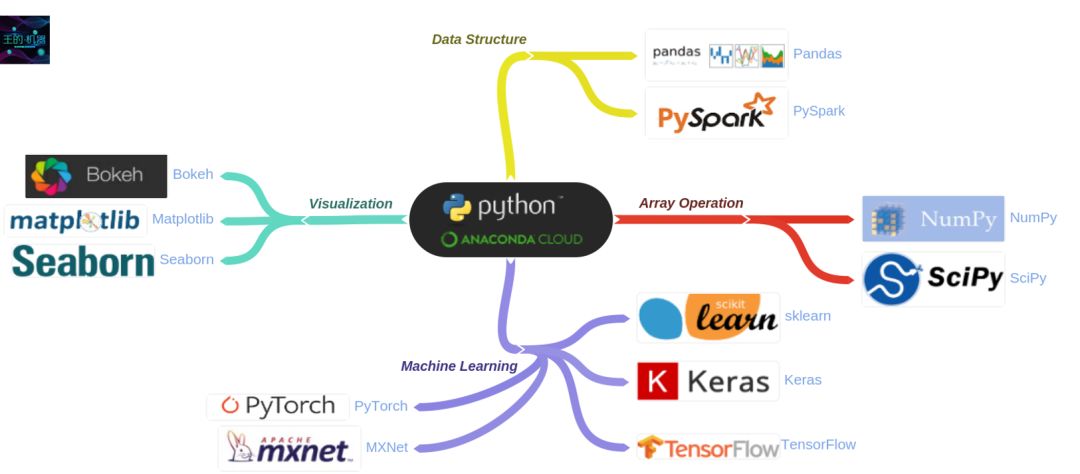
Numpy和pandas是python当中两个非常重要的库,用于配合科学运算和矩阵处理。程序是算法与数据的结合,二者缺一不可,而numpy和pandas就是python中用于处理数据的利器,因此学习这两个package的使用非常重要。在使用matplotlib和seaborn进行数据可视化的时候,就会发现,所有作图的关键在于数据格式的把控,这两个package所提供的API就像是图表的模具,而整理好相应格式的数据就是原料,numpy和pandas就是整理数据的工具。接下来让我们开始学习这两个package吧。在这一篇博客中我们先学习numpy。
这是一幅python_package的总览图,由此我们可以大概了解,有哪些很值得我们学习的package。
在得到了测序结果之后,我们需要评估一下测序的质量,因此我们需要对测序的数据进行统计评价,这里采用的软件组合就是fastqc和multiqc,fastqc用于对每一组的测序结果进行评价并且输出html结果文件,但是当同时有比较多组的测序数据时,一份份html文件去翻阅是非常麻烦的,此时multiqc就派上用场了,multiqc可以对这些结果进行整合,生成一份html文件,方便查阅。
为什么要进行质量评价呢?因为我们后期的所有分析都是基于测序数据展开的,测序数据质量的高低直接影响了我们分析的结果,因此在所有分析步骤之前,我们必须要对测序的数据的质量进行评价,只有达到我们的要求的测序数据才能用于下一步分析。