
前言
因为工作原因,需要在通过地图接口下载数据,于是尝试了一下通过腾讯地图的接口进行下载,下载效果还不错,所以在此记录一下过程。
腾讯地图接口
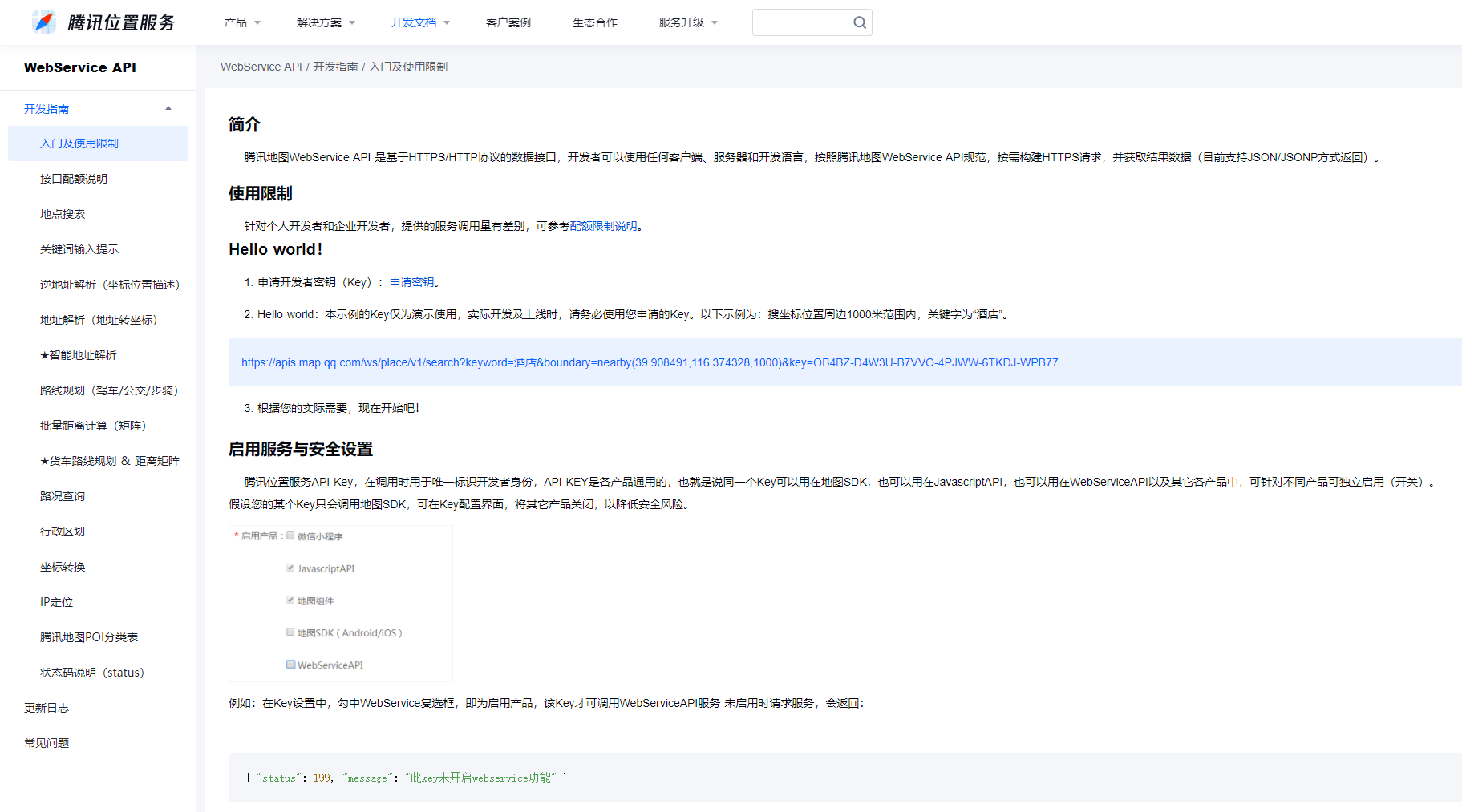
由下图可知,腾讯地图的位置服务提供了对应的开发者接口,通过调用这些接口,我们可以获取对应的一些数据,比如城市的位置/名称/经纬度等等信息,当我们需要批量采集数据的时候,用起来效果还不多。如下图,这就是开发者文档,根据文档进行操作,我们就可以流畅的使用接口下载数据了。学习文档链接
因为工作原因,需要在通过地图接口下载数据,于是尝试了一下通过腾讯地图的接口进行下载,下载效果还不错,所以在此记录一下过程。
由下图可知,腾讯地图的位置服务提供了对应的开发者接口,通过调用这些接口,我们可以获取对应的一些数据,比如城市的位置/名称/经纬度等等信息,当我们需要批量采集数据的时候,用起来效果还不多。如下图,这就是开发者文档,根据文档进行操作,我们就可以流畅的使用接口下载数据了。学习文档链接
什么是爬虫?爬虫有什么作用?在哪有爬虫?对于数据分析师而言并不陌生,但是对于毫无编程经验的人来说,这可能就是一个很迷惑的名词了。其实“爬虫”指的是在互联网中的自动下载器,因为这个自动下载的过程就像是虫子在互联网的大网上爬动寻找到的,所以生动形象的称为“爬虫”,如百度、Google等搜索引擎的网页索引,都是通过对全网的数据进行爬取下载后建立的,所以其实爬虫和我们的生活非常密切,毕竟每个互联网民在网上获取信息时都会使用搜索引擎,甚至我们每天都需要使用这些服务,与我们的生活和工作都分不开,而搜索引擎的服务就是建立在爬虫获取全网信息的基础上的。那我们能不能也利用爬虫来帮自己获取信息呢?当然可以。所以接下来我们先系统了解一下爬虫。
Numpy和pandas是python当中两个非常重要的库,用于配合科学运算和矩阵处理。程序是算法与数据的结合,二者缺一不可,而numpy和pandas就是python中用于处理数据的利器,因此学习这两个package的使用非常重要。在使用matplotlib和seaborn进行数据可视化的时候,就会发现,所有作图的关键在于数据格式的把控,这两个package所提供的API就像是图表的模具,而整理好相应格式的数据就是原料,numpy和pandas就是整理数据的工具。接下来让我们开始学习这两个package吧。在这上一篇博客中我们学习了numpy,这一篇博客中我们来学习pandas。
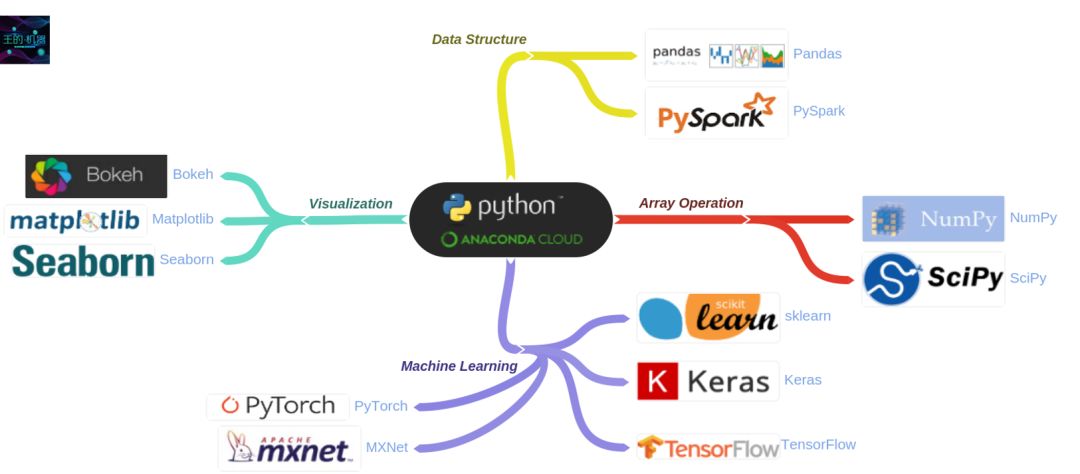
这是一幅python_package的总览图,由此我们可以大概了解,有哪些很值得我们学习的package。
Numpy和pandas是python当中两个非常重要的库,用于配合科学运算和矩阵处理。程序是算法与数据的结合,二者缺一不可,而numpy和pandas就是python中用于处理数据的利器,因此学习这两个package的使用非常重要。在使用matplotlib和seaborn进行数据可视化的时候,就会发现,所有作图的关键在于数据格式的把控,这两个package所提供的API就像是图表的模具,而整理好相应格式的数据就是原料,numpy和pandas就是整理数据的工具。接下来让我们开始学习这两个package吧。在这一篇博客中我们先学习numpy。
这是一幅python_package的总览图,由此我们可以大概了解,有哪些很值得我们学习的package。
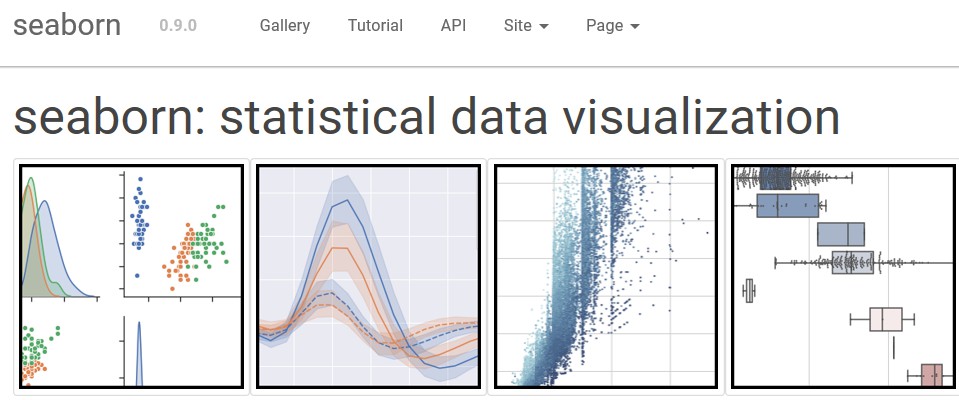
New package for data visualization. This package is base on the matplotlib, numpy, scipy , and pandas. The shining point is that this package is easier for people to create a beautiful picture for your dataset, this is essential for the data science. So let’s get it. This is the official URL: http://seaborn.pydata.org/
You can turn to there for help.
- Seaborn是基于matplotlib的图形可视化python包。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。
- Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplotlib的补充,而不是替代物。同时它能高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。
- seaborn 有五种风格,分别为”darkgrid”, “whitegrid”, “dark”, “white”, “ticks”

开始学习数据可视化,在此记录,目前主要是先学Python中的matplotlib这个包,这个包和MATLAB中的作图很相似,具有很高的自定义性,等到这个学习的比较深入后再考虑了解拓展其他工具的作图。附上学习链接:https://matplotlib.org/gallery/index.html
直接到官网学习是最方便的,文档详细,demo生动。
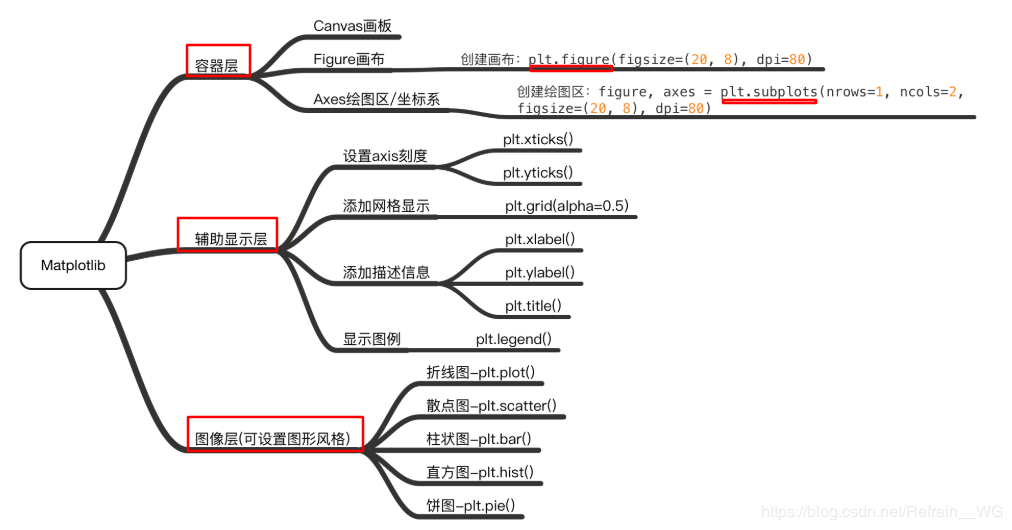
这是新发现的一张思维导图,非常清晰的展示了matplotlib的结构,非常helpful。

这是一篇关于python基础知识复习的博客,除了基础之外,还会涉及进阶以及算法设计。
Python的创始人为Guido van Rossum
Python 的设计目标:
- 一门简单直观的语言并与主要竞争者一样强大
- 开源,以便任何人都可以为它做贡献
- 代码像纯英语那样容易理解
- 适用于短期开发的日常任务
Python设计哲学
- 优雅、明确、简单
Python开发者的哲学是:用一种方法,最好只有一种方法来做一件事
Python是完全面向对象的语言,在Python中一切皆对象
可扩展性:如果需要一段关键代码运行的更快或者希望某些算法不公开,可以把这部分程序用
C或者C++编写,然后在Python程序中使用它们。